
建設DevOps統一運維監控平臺,先從日志監控說起
發布時間:2018-02-12 瀏覽:1018打印字號:大中小
面對動輒幾百上千個虛擬機、容器,數十種要監控的對象,現有的監控系統還能否支撐的住?來自于容器、虛擬機、物理機的應用日志、系統服務日志如何采用同一套方案快速、完整的收集和檢索?怎樣的架構、技術方案才更適合如此龐大繁雜的監控需求呢?本文主要從以下幾個方面來分享在日志監控方面的一些經驗。
一、DevOps浪潮下帶來的監控挑戰
現在Devops、云計算、微服務、容器等理念正在逐步落地和大力發展,機器越來越多,應用越來越多,服務越來越微,應用運行基礎環境越來多樣化,容器,監控面臨的壓力越來越大。挑戰主要有:

監控源的多樣化挑戰 ?業務、應用、網絡設備、存儲設備、物理機、虛擬機、容器、數據庫、各種系統軟件等等,需要監控的對象越來越多,指標也多種多樣,如何以一個統一的視角,監控到所有的數據?
海量數據的分析處理挑戰 ?設備越來越多,應用越來越多,要監控的數據自然也排山倒海般襲來,怎樣的監控系統才能應對大數據的采集、存儲和實時分析展現呢?
軟硬件數據資源的管理分析挑戰 ?數據是采集到了,采集全了,那么如何對他們進行分析呢?應用、系統軟件和運行環境、網絡、存儲設備的關聯關系是否能準確體現呢,某個點發生了故障、問題影響的鏈路是否能快速找到并進行處理呢?監控離不開和軟硬件資源管理的結合。
面對這些挑戰,是否感覺壓力山大呢?一個監控平臺,擁有哪些能力才能滿足如此大的挑戰呢?
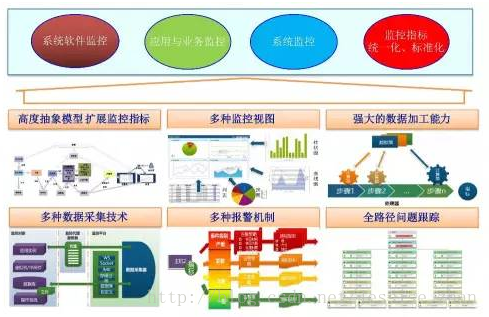
高度抽象模型,擴展監控指標:正如之前所說,監控源、指標的多樣化,要求我們必須要進行監控模型的高度抽象,并且針對于指標可以動態擴展,這樣才能保證監控平臺的健壯性和可擴展性。
多種監控視圖:監控數據自然不能只是簡單的表格展現,餅圖、柱狀圖、折線圖、儀表盤等等,監控的數據需要結合實際情況選擇優質的圖標展現。
強大的數據加工能力:海量的數據必須要有足夠強大的數據加工、分析處理能力才能得到直觀的結果。
多種數據采集技術:數據源的不同決定了采集的技術也是有區別的。
多種報警機制:短信、郵件、企業內部通訊工具等等,結合不同場景選擇不同的報警機制。
全路徑問題跟蹤:一個請求有可能牽扯到數個系統、數十個接口的調用,出了問題有可能是其中任何一個環節,也有可能是應用所處運行環境、網絡、存儲的問題,所以問題的定位離不開全路徑的跟蹤。
統一監控平臺由七大角色構成:監控源、數據采集、數據存儲、數據分析、數據展現、預警中心、CMDB(企業軟硬件資產管理)。
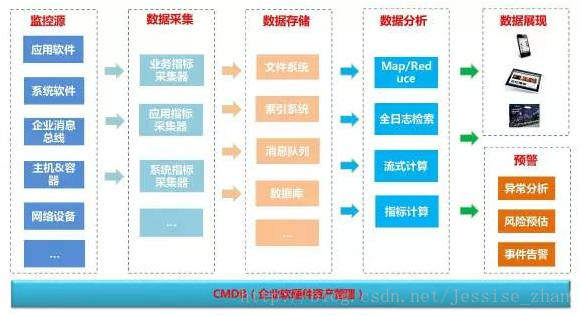
監控源 ?從層次上來分,大致可以分為三層,業務應用層、中間件層、基礎設施層。業務應用層主要包括應用軟件、企業消息總線等,中間件層包括數據庫、緩存、配置中心、等各種系統軟件,基礎設施層主要有物理機、虛擬機、容器、網絡設備、存儲設備等等。
數據采集 ?數據源如此多樣,數據采集的任務自然輕松不了。數據采集從指標上劃分可以分為業務指標、應用指標、系統軟件監控指標、系統指標。
應用監控指標如:可用性、異常、吞吐量、響應時間、當前等待筆數、資源占用率、請求量、日志大小、性能、隊列深度、線程數、服務調用次數、訪問量、服務可用性等,業務監控指標如大額流水、流水區域、流水明細、請求筆數、響應時間、響應筆數等,系統監控指標如:CPU負載、內存負載、磁盤負載、網絡IO、磁盤IO、tcp連接數、進程數等。
從采集方式來說通常可以分為接口采集、客戶端agent采集、通過網絡協議主動抓取(http、snmp等)
數據存儲 ?采集到的數據一般都會存儲到文件系統(如HDFS)、索引系統(如elasticsearch)、指標庫(如influxdb)、消息隊列(如kafka,做消息臨時存儲或者緩沖)、數據庫(如mysql)
數據分析 ?針對采集到的數據,進行數據的處理。處理分兩類:實時處理和批處理。技術包括Map/Reduce計算、全日志檢索、流式計算、指標計算等,重點是根據不同的場景需求選擇不同的計算方式。
數據展現 ?將處理的結果進行圖表展現,在多屏時代,跨設備的支持必不可少。
預警 ?如果在數據處理過程發現了問題,則需要進行異常的分析、風險的預估以及事件的觸發或告警。
CMDB(企業軟硬件資產管理) ?CMDB在統一監控平臺中是很重要的一環,監控源雖然種類繁多,但是他們大都有著關系,如應用運行在運行環境中,應用的正常運行又依賴網絡和存儲設備,一個應用也會依賴于其他的應用(業務依賴),一旦其中任何一個環節出了問題,都會導致應用的不可用。CMDB除了存儲軟硬件資產外,還要存儲這樣一份資產間的關聯關系,一個資產發生了故障,要能根據這個關系迅速得知哪些其他的資產會被影響,然后逐一解決問題。
三、日志監控的技術棧

既然前面講了整個監控系統的架構,下面就按照架構中的角色來分類看看有哪些常用的開源技術。由于篇幅原因,這里無法詳細描述每一個技術的細節,大家感興趣的話,可以一一了解下。
日志源
syslog 守護進程的任務是記錄系統日志。它從應用程序和服務中獲取格式各異的日志消息并保存到磁盤上,消息的元數據是組件名、優先級、時間戳、進程標簽和 PID,日志格式很是寬泛,沒有定義結構化的格式,所以系統的分析和日志消息處理也就變得十分混亂,同時性能和其他的一些缺點隨著時間推移也慢慢被放大,后來慢慢被Rsyslog所取代。
Rsyslog可以說是Syslog的升級版,它涵蓋SysLog的常用功能,不過在功能和性能上更為出色。
Red Hat Enterprise Linux 7與SUSE Linux Enterprise Server 12這些新一代的Linux發行版本使用systemd管理服務。
journal是systemd的一個組件,由journald處理。Journald是為Linux服務器打造的新系統日志方式,它標志著文本日志文件的終結,它不再存儲日志文件,而是將日志信息寫入到二進制文件,使用journalctl閱讀。它捕獲系統日志信息、內核日志信息,以及來自原始RAM磁盤的信息,早期啟動信息以及所有服務中寫入STDOUT和STDERR數據流的信息。Journald快速改變著服務器如何處理日志信息與管理員如何訪問的方式。
數據采集
日志的采集工作大都是通過客戶端進行,客戶端除了一些直接可用的工具(如fluentd、flume、logstash)外,還可以通過log4j的appender、自行寫腳本實現等。
fluentd是開源社區中流行的日志收集工具,fluentd基于CRuby實現,并對性能表現關鍵的一些組件用C語言重新實現,整體性能相當不錯。優點是設計簡潔,pipeline內數據傳遞可靠性高。缺點是相較于logstash和flume,其插件支持相對少一些。
flume是由JAVA實現的一個分布式的、可靠的、高性能、可擴展的的日志收集框架,Flume比較看重數據的傳輸,使用基于事務的數據傳遞方式來保證事件傳遞的可靠性,幾乎沒有數據的解析預處理。僅僅是數據的產生,封裝成event然后傳輸。同時使用zookeeper進行負載均衡,不過JVM帶來的問題自然是內存占用相對較高。
Logstash相比大家都比較熟悉了,是ELK中的L,logstash基于JRuby實現,可以跨平臺運行在JVM上。logstash安裝簡單,使用簡單,結構也簡單,所有操作全在配置文件設定,運行調用配置文件即可。同時社區活躍,生態圈提供了大量的插件。早期Logstash并不支持數據的高可靠傳遞,所以在一些關鍵業務數據的采集上,使用logstash就不如flume更加可靠。不過在5.1.1版本發布了持久化隊列的beta版,顯然logstash也在快速改進自己的缺陷。
數據緩沖
在大批量的監控數據涌過來后,考慮到網絡的壓力和數據處理的瓶頸,一般會在存儲前先經過一層數據緩沖,將采集到的數據先放置到消息隊列中,然后再從分布式隊列中讀取數據并存儲。這張圖是新浪的日志檢索系統的架構圖,可以看到數據采集后,經過kafka緩沖,然后再使用logstash去讀取kafka中的數據并存儲到es中:
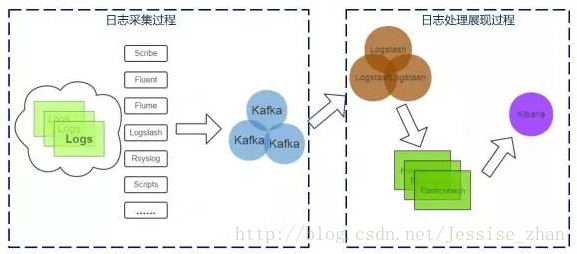
關于分布式隊列這里就不詳細講解了,常用有kafka,rabbitmq,zeromq等。
數據存儲&分析 ?存儲和分析息息相關,監控數據的處理通常分為實時處理和非實時處理(如大數據的批處理框架hadoop等),如Elasticsearch就是一個實時的分布式搜索和分析引擎,它可以用于全文搜索,結構化搜索以及分析。
除了ES外,還有一些流式大數據處理框架可以做到實時或者準實時的處理大數據流。如Spark和Storm。關于大數據處理的內容因為本人也沒有多少實踐經驗,就不在此多做分享了。后面主要還是針對于Elasticsearch這一框架進行介紹。
數據展現 ?Kibana和Elasticsearch可以說是無縫銜接,再加上Logstash,組成的ELK赫赫有名,很多企業都會直接采用這一種框架。
Kibana確實也能滿足大部分的監控需求,但是其畢竟只能依靠現有的數據進行展現,如果需要和外部數據結合處理,就會無法滿足了,并且在自己構建一個統一監控平臺時,需要將日志和性能等監控數據結合CMDB、預警中心、等統一展現,所以對于kibana的替換就無法避免了。我們是通過使用JAVA去查詢Elasticsearch的數據,結合其他數據統一分析,將展現的結果進行滾動展現或者用圖表顯示。
(本文轉自微信號EAWorld)

